
Claude 4.5, AI 텍스트 아레나에서 1위 동점
Anthropic의 주력 모델이 AI 경쟁에서 중요한 순간을 맞이하며 Google의 Gemini와 함께 리더보드 정상을 차지했습니다.
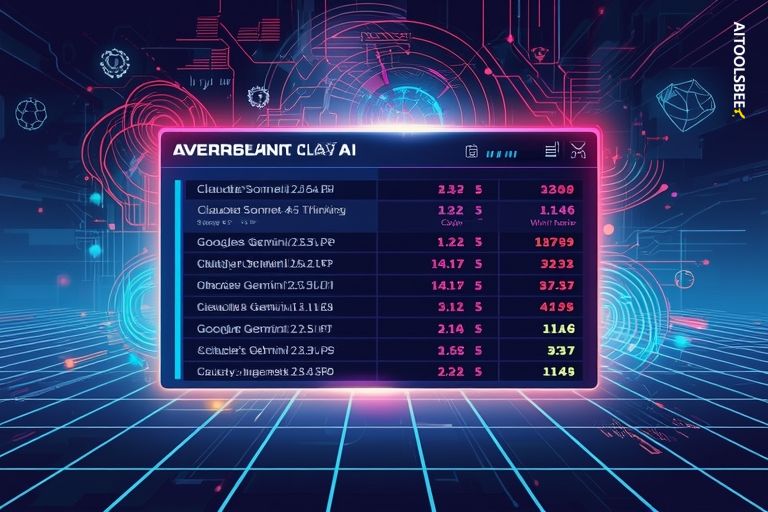
AI 분야의 경쟁이 더욱 치열해졌습니다. Anthropic의 Claude Sonnet 4.5 Thinking이 공식적으로 텍스트 아레나 순위에서 1위를 기록하며 대형 언어 모델의 실제 성능을 측정하는 벤치마크에서 Google과 OpenAI와 어깨를 나란히 했습니다. 이는 AI 주요 플레이어 간의 지속적인 경쟁에서 중요한 순간을 나타냅니다.
이 성과는 AI 커뮤니티에서 축하받고 있으며, 최근 Lisan al Gaib의 트윗에서 강조되었습니다. 최신 리더보드는 매우 치열한 경쟁을 보여줍니다. Claude Sonnet 4.5 Thinking은 32k 컨텍스트 윈도우로 1453점을 기록하며 Google의 Gemini 2.5 Pro와 1452점으로 공동 1위를 차지했습니다. 그 뒤를 Claude Opus 4.1 Thinking이 1449점으로 따르고 있으며, OpenAI의 GPT-4 및 실험적인 GPT-5 변형 모델이 1440-1441점 사이에 위치해 있습니다.
Claude의 'Thinking' 시리즈는 고급 추론 및 다단계 논리를 위해 설계되었으며, 복잡한 연구 종합, 정교한 코딩 작업 및 미묘한 전문 문제 해결에서 뛰어난 성과를 보입니다. 이 강력한 성과는 Anthropic의 아키텍처 선택이 효과적임을 입증합니다. 회사는 기존 거인들과의 눈에 띄는 격차를 해소하면서도 신중한 AI 안전 관행에 대한 명성을 유지하고 있습니다.
우리는 OpenAI와 Google 간의 양자 경쟁에서 진정한 삼자 경쟁으로 전환했습니다. 이 경쟁은 혁신을 촉진하며, 각 플레이어가 다른 플레이어를 앞으로 나아가게 합니다. 이러한 모델들이 매우 비슷한 성능을 보이기 때문에, 차별화는 점점 가격, API 신뢰성, 컨텍스트 윈도우, 안전 기능 및 워크플로우 통합과 같은 요소에 달려 있을 것입니다.