- リリース日
- 2018年6月
- 月間訪問者数
- 18.1万
- 開発国
- アメリカ
- プラットフォーム
- ウェブ
- 言語
- 英語
キーワード
- ML実験管理
- モデルバージョン管理
- ML配布プラットフォーム
- MLflowの使い方
- 機械学習プラットフォーム
- MLOpsツール
- ML追跡システム
- 実験再現性
- Pythonロギング
- MLプラットフォームの比較
プラットフォームの説明
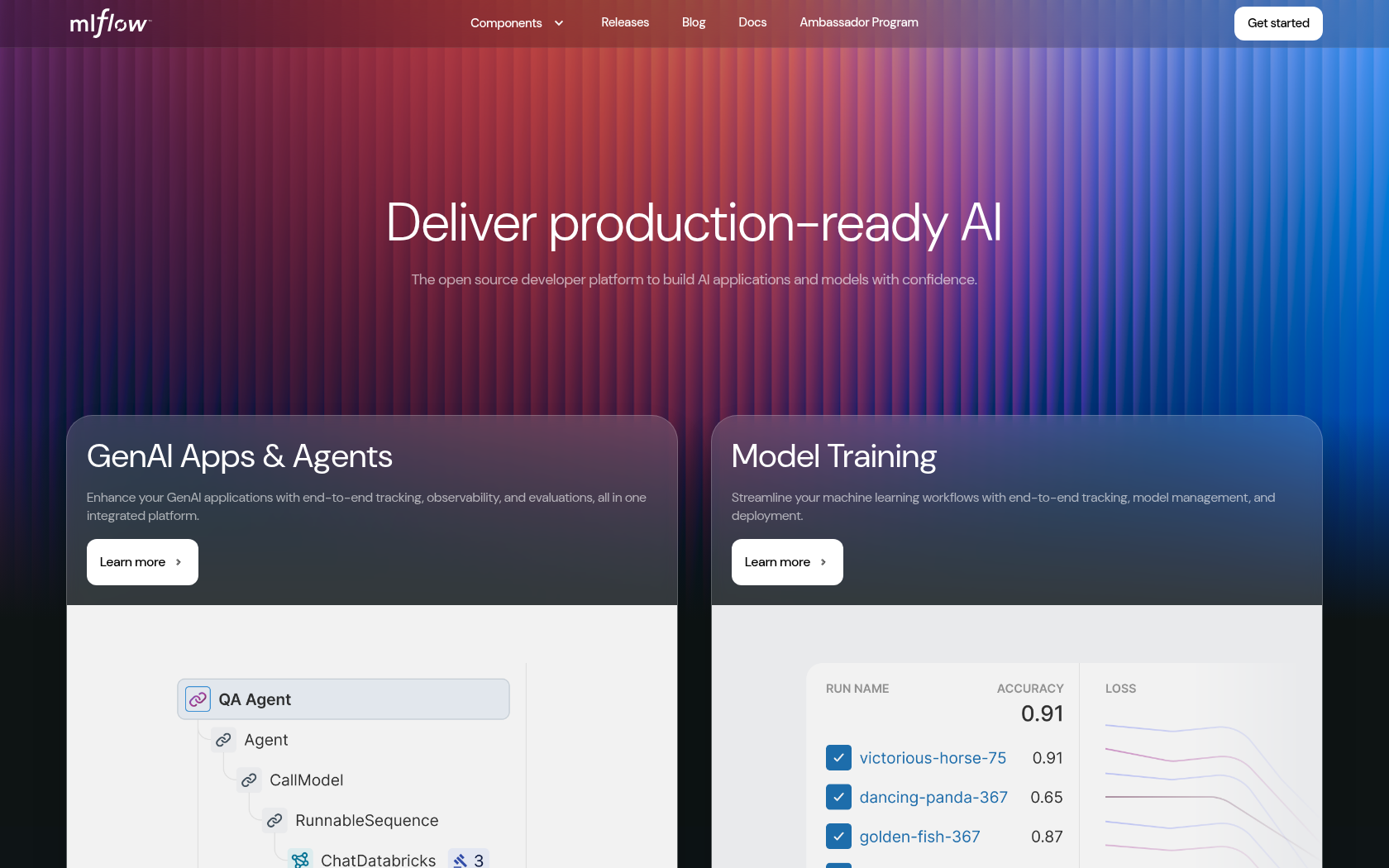
MLflow(エムエルフロー)は、機械学習のライフサイクルを包括的に管理するためのオープンソースプラットフォームであり、実験管理、モデル登録および配布、プロジェクトの再現性確保、モデルサービングを一つの統合ワークフローで提供します。実験段階では、ハイパーパラメータ、メトリック、アーティファクトなどを自動的にログに記録することができ、ユーザーは様々な実験を比較・分析・反復することができます。プロジェクト段階では、MLflowプロジェクトフォーマットに基づいて環境構成と実行コマンドを定義することができ、Gitベースのリポジトリと連動して様々なチーム内/外部と協業することができます。特に、MLflow Modelは様々なフレームワーク(PyTorch、TensorFlow、scikit-learnなど)で学習されたモデルを一つの標準形式でラップしてくれるので、配布環境や言語に関係なく、再利用性と移植性に優れているのが特徴で、REST APIベースのサーブ、Azure、SageMaker、Databricksなどのクラウドプラットフォームとの統合もスムーズです。エンタープライズ組織では、MLflow TrackingとRegistryを内部MLOpsパイプラインに連動して反復的で大規模なモデル管理に使用し、オープンソースベースなので、オンプレミスまたはクラウド環境で柔軟にカスタマイズが可能です。
コア機能
-
実験の追跡と可視化
実験ごとのパラメータ、メトリック、アーティファクトのロギングと比較
-
モデル登録とバージョン管理
モデルレジストリ機能で名前ベースの登録とバージョン分岐が可能
-
モデルサービング
REST APIベースのモデルサービングをサポートし、ローカル/リモートデプロイメント連動をサポートします。
-
MLflowプロジェクト
実行環境定義と自動化実行のためのフォーマット設定
-
MLflowモデル 포맷
様々なフレームワークモデルを一つの標準フォーマットで保存
-
クラウド連動をサポート
AWS、Azure、DatabricksなどのMLOps環境との統合が可能
-
ローカル/オンプレミス設置をサポート
オープンソースベースで内部サーバーの設置及びカスタマイズが可能
-
自動化スクリプトとCLI
コマンドベースのタスクの自動化が可能、DevOpsに容易
活用事例
- モデル実験比較
- ハイパーパラメータチューニング
- モデル配布の自動化
- モデル再現性検証
- チームベースのMLコラボレーション
- ダッシュボードの共有
- データに基づく実験の反復
- モデルサービング
- レガシーモデル管理
- Git連動実験
- Pythonロギング
- クラウドML追跡
- 大規模モデルのバージョン管理
- エンタープライズMLOpsの構築
- オープンソースの機械学習ツール
使用方法
基本サーバー駆動
APIから実験ロギングを開始
実験結果の比較・分析
モデルをRegistryに登録し、REST APIでサービングする
料金プラン
| 料金プラン | 価格 | 主な特徴 |
|---|---|---|
| オープンソースMLflow | $0 | • 実験追跡 • モデルレジストリ • プロジェクト実行 • モデル保存と読み込み • カスタムストレージ設定 • RESTとPython API提供 • ローカルモデル提供 • 自由な配布環境 • サーバー費用、ストレージ、DBユーザー負担 |
| Databricks MLflow | $0.07~0.95/DBU | • 自動実験追跡 • 高度なモデルレジストリ • ワンクリックモデルサービング • タスクスケジューリングとパイプライン • サーバーレスクラスター統合 • セキュリティと権限管理 • ダッシュボードと分析連動 • コラボレーションベースのノートブック環境 |
よくあるご質問
-
MLflowは、機械学習実験とモデルを管理するオープンソースプラットフォームです。 MLモデルを作成する際に発生する実験データ、コードバージョン、ハイパーパラメータ、モデル結果、配布過程を一つの体系の中で追跡・管理・再現することができます。 開発者とデータサイエンティストがMLプロジェクトをより体系的かつ協業的に進めることができます。
-
主な構成要素は4つです: - Tracking - 実験のパラメータ、メトリック、結果ファイルなどの記録 - Projects - コード、環境、依存性を再現するための構造化された実行方式 - Models - 様々なフレームワークのモデルを保存および配布可能 - Registry - モデルを運用/テストバージョンで管理し、承認フローを適用します。
-
MLflow自体は無料です。 MLflowはオープンソースの機械学習運営ツールで、Apache 2.0ライセンスの下で誰でも自由に使用することができます。ただし、自分でサーバー、ストレージ、DBなどを構成する必要があり、これに対するインフラ費用は自分で負担する必要があります。
-
Databricksが提供するMLflowは14日間の無料体験は可能ですが、正式使用は有料です。 DatabricksはMLflowをウェブUI、自動実験追跡、モデルサービング機能などと統合して提供しています。この時はDBU(Databricks Unit)基準で使用した分だけ課金されます。使用した分だけ支払い、14日間の無料体験版があります。
-
いいえ、Databricksでは別途DBやストレージを構成する必要はありません。 Databricksはサーバーレス環境であり、実験情報、モデル、アーティファクトの保存を自動的に管理します。ユーザーはML実験を実行したり、ノートブックに記録するだけです。 このすべてのインフラストラクチャリソースは、DBU単価に含まれて課金されます。
-
使用量基準(DBU)課金です。 - CPUベース:約$0.15〜$0.40/DBU - 高度な機能を含むプラン:$0.55/DBU以上 - GPU、モデルサービング、SQLウェアハウスなどは別途単価の体験版は14日間無料、その後、決済手段を登録する必要があり、引き続き使用可能です。
-
MLflowはApache 2.0ライセンスの下で単独でインストールして使用可能なオープンソースプラットフォームです。ローカル環境、クラウドVM、オンプレミスサーバーなどに自由に展開することができます。DatabricksはMLflowをエンタープライズ環境に合わせて統合・拡張して提供する形態です。
-
いいえ、MLflow独自のAPIは無料です。オープンソースインストールバージョンでREST APIやPython APIを使用するためには追加料金は発生しません。 ただし、Databricks環境では、API呼び出しによるコンピューティングリソース使用量が料金に反映される場合があります。
⚠ 情報に誤りや不足がある場合は、以下のボタンをクリックしてお知らせください。迅速に確認し、反映いたします。